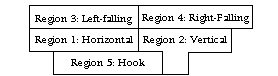
Diagram 1: Keyboard Region/Direction
In this computer age, the written Chinese language may seem simply too complex to survive. With more than 40,000 characters lacking any phonetic information, such as letters, it is difficult to imagine a keyboard that could include every character and the skill necessary to master such a keyboard.
Necessity has produced many methods of typing, usually much more efficient than the one just proposed. Unfortunately, among these methods an inverse relationship exists between the amount of time necessary to master the method and the efficiency of the method.
For example, the popular Pinyin method requires little training; one need only transliterate the character being entered into English letters. However, since multiple characters correspond to a single pronunciation, isolating the desired character from a list of many, does slow and interrupt the process. In addition, phonetic input methods that use one Chinese dialect are unusable by speakers of another dialect.
五笔字型 (Wu3bi3zi4xing2) solves both the dialect problem and the speed problem. Wubi, as this text will refer to the method, has these advantages:
Every Chinese character can be broken down into its root characters, or 字根 (zi4gen1). Conversely, characters can be built by combining these roots. For example, observe the composition of 李 (li3), a common family name:
木 + 子 = 李
In addition, observe the composition of 明 (ming2), which means bright:
日 + 月 = 明
This idea -- that characters can be built by combining roots -- is the fundamental principle behind the Wubi input method. The keyboard contains five regions, organized by the direction of the root's first stroke. Each region contains five keys (making twenty-five keys in total), and each key contains a number of character roots. Diagram 1 shows the regions of the Wubi keyboard:
Diagram 1: Keyboard Region/Direction
To continue the 李 and 明 examples, observe in which regions (either 1, 2, 3, 4, of 5) the roots of these characters would fall.
李:
明:
In addition, an example of a root character from Region 4 is 之. Notice that it begins with a right-falling stroke, which often appears as a dot.
Just as we refer to each region by its number, we refer to each key as a combination of both its region and its key number within the region. For example, Diagram 1 shows that G is in the first region and that it is the first key in that region. Therefore, G is 11. Moving leftward, the second key, F, is 12. The last key in the first region, A, is 15. Each region proceeds in the same manner, from the inner-most key on the keyboard to the outer-most.
We will refer to the individual keys by the key number and letter: neither 12 nor F, but 12F. Thinking of the keys in this notation will help your conceptual understanding of Wubi. However, we will refer to the Wubi codes, composed of multiple keys, by only the letters: JQVO, for example.
The Basic Keyboard Diagram, below, shows the essential though incomplete Wubi keyboard: the keys (like 11G and 15A) and the representative root character for each key. The representative root is the root which is most similar to the other roots on its key, and therefore learning the representative roots simplifies memorization of the complex Wubi keyboard, shown on Diagram 3.
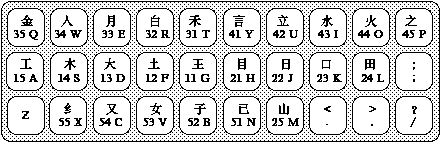
Diagram 2: Basic Keyboard Diagram
Diagram 2 shows that the representative root of 41Y is 言, whose first stroke is one dot, or one right-falling stroke. Diagram 3 shows that the other roots on 41 also contain just one right-falling stroke: 文, 方, and 广. The representative root for 42U is 立, which contains two dots (the dots between the horizontal lines), and the other roots on 42U also contain two dots: 六, 丬, and 辛. The more-detailed Note the similarity between the representative root -- also shown in Diagram 3 as the top-left root on each key -- and the other roots on each key.
In general, the roots are placed logically so as to assist the user`s memory. 11G, in the horizontal region, includes the root 一 (yi1); 12F includes 二 (er4); and 13D includes 三 (san1). Be careful, however, because 四 (si4) begins with a vertical stroke; so it fits on 24L, not 14S.
"Leftover" roots -- the roots that do not fit into this pattern -- often appear on the fifth key of each region. These keys are the most difficult to memorize.
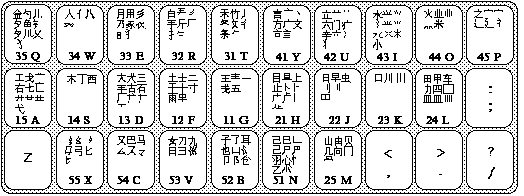
Diagram 3: The Complete Wubi Keyboard
Click here for a larger, higher-quality keyboard diagram. At first, the arrangement of the keys may seem arbitrary and overwhelming. With consistent practice and experience, though, the knowledge will come. Keep reading.
[TOP]
In the introduction, it was mentioned that, with Wubi, any character can be entered with four or less keystrokes. But what about characters that contain more than four roots? The rule is to enter the first three root characters as usual, but to enter the final root as the fourth key. For example, the character 输 contains five roots: 车 + 人 + 一 + 月 +刂. But, according to this rule, only the first three and the last are entered. Thus, the code is 24L + 34W + 11G + 22J. Check this with Diagram 3, above, if necessary.
A representative root can be typed by entering its key four times. The Wubi code for 言, the representative root of 41Y, is YYYY.
When a character appears on a key but is not a representative root: First, type the key that the character lies on. Second, build the character by entering the key that contains the its first stroke. Third, enter the key that contains its second stroke. Finally, enter the key that contains its final stroke. For example, 五 (wu3) is on 11G, but it is not the representative character. The first stroke, 一, is on 11G. The second stroke, 丨, is on 21H. The final stroke, 一, is on 11G. Thus, the code for 五 is GGHG.. These building strokes are always 一, 丨, 丿, 丶, or 乙; they are always found on 11G, 21H, 31T, 41Y, or 51N.
If the character has only one or two strokes, fill in the remainder of the code with L. For example, 丿is on 31T, is not a representative root, and only contains one stroke: Thus its code is TTLL.
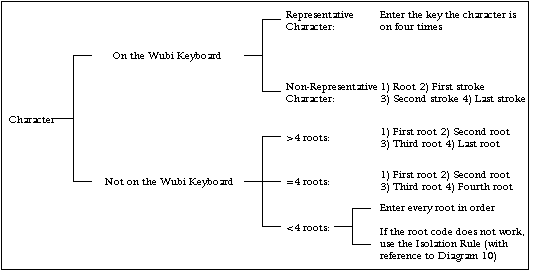
Wubi provides many typing shortcuts, often allowing the user to enter only a portion of a character's complete code to produce it. A character has a reduced code under three circumstances: First, when Wubi logic has eliminated all other characters based on the code already entered; and/or second, when the character is a commonly-used character (and therefore was given a shorter code before other, less-commonly-used characters); and/or third, when the character is one of the 25 first level characters (whose codes consist of a single key).
An example of the first case is 魏 (wei4). In its verbose form, the code for 魏 is TVRC. However, no other characters have the code TVR followed by another key (such as TVRK or TVRA). Therefore, TVR will produce 魏.
An example of the second case is 笔 (bi3). In its verbose form, the code for 笔 is TTFN. Whereas other characters exist with the codes containing TT, such as 禾 (TTTT), 笑 (TTDU), 竹 (TTGH), and 笮 (TTHF), 笔 is perhaps the most commonly-used of the group. Therefore, rather than giving a less-commonly-used character the reduced code, Wubi has assigned the code TT to 笔.
An example of the third case is 和 (he2). Meaning "and," it is an often-used character. In its verbose form, the code for 和 is TKG; however, it has a shortened code: T. Similarly, the verbose code for 是 (shi4), which means "is," is JGH; its shortened code is J. With a few exceptions, the shortened code is, logically, always derived from the verbose code. The first level characters will be listed before every section in the next chapter.
Both the verbose and shortened code will produce the character, but clearly the former is more efficient. This is just another way that Wubi logic speeds up typing. We will return to the shortcuts while presenting more examples of typing.
It is especially important for students of Chinese to keep an open mind about stroke order and the roots that make up a character. Although most characters can be broken down into the roots that appear on the Wubi keyboard easily, some are tricky. Therefore, when all else fails, try to think of the character in a different way; think of the roots in a different configuration.
The remaining rules require actual Wubi experience to understand; therefore, we shall begin with practicing with the regions right away!
[TOP]

Diagram 4: Region 1
Glance over region 1 and get a general sense of the roots on each key. Be ready to start forming associations in your mind. Remember that every root begins with a horizontal stroke.
First, which characters have single-key codes? What are, in other words, the first level characters of region 1? The first level characters are as follows:
G: 一 F: 地 D: 在 S: 要 A: 工
Note that the root of each character lies on its corresponding key.
We will now analyze some sample characters, following the rules of Wubi typing that have been outlined.
| 林: | The first root character, 木, begins with a horizontal stroke, so we look to region 1. Glancing over the region 1 keys, we see that 木 is in 14S. The second root is the same, so we type 14S for it, too. Thus, the code for 林 is SS. |
| 开: | The first root, 一, is in region 1 and resides on key 11G. The second root, 廾, is also in region 1 but resides on 15A. Thus, the code for 开 is GA. |
| 夺: | The first root, 大, is in region 1 and resides on key 13D. The second root, 寸, is on 12F, so the code for 夺 is DF. |
| 西: | This character is on key 14S, but it is not the representative root. Therefore, we first enter the key that it resides on, 14S. Next, we enter the strokes: 1, 2, and 4. The first stroke, 一, is on 11G. The second stroke, 丨, is on 21H. The last stroke, 一, is on 11G. Therefore, the code for 西 is SGHG. |
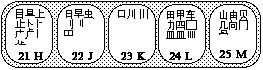
Diagram 5: Region 2
Glance over region 2 and get a general sense of the roots on each key. Remember that every root begins with a vertical stroke.
The first-level characters are as follows:
H: 上 J: 是 K: 中 L: 国 M: 同
Note that the root of each character lies on its corresponding key.
We will now analyze some sample characters, following the rules of Wubi typing that have been outlined, as well as incorporating Region 1 into the examples.
| 另: | The first root, 口, is in Region 2 and resides on key 23K. The second root, 力, is also in region 2 but resides on 24L. Thus, the code for 另 is KL. |
| 贞: | The first root, 卜, is in Region 2 and resides on key 21H. The second root, 贝, is also in region 2 but resides on 25M. Thus, the code for 贞 is HM. |
| 曙: | The first root, 日, is in Region 2 and resides on key 22J. The second root, 皿, is in Region 2 but resides on 24L. The third root, 土, is in Region 1 and resides on 12F. The last root, 日, is on 22J. Thus, the code for 曙 is JLFJ. |
| 贝: | This character is on 25M, but is not a representative root. The rule is to enter the key that the character lies on and then build the character from its strokes. Therefore, the first key is 25M. The first stroke of the character is 丨, so the next key is 21H. The second stroke is a hook, so the third key is 51N. The last stroke of the character is 丶, so the last key is 41Y. Thus, the code for 贝 is MHNY. |
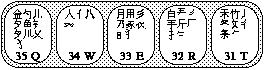
Diagram 6: Region 3
Glance over region 3 and get a general sense of the roots on each key. Remember that every root begins with a left-falling stroke.
The first-level characters are as follows:
T: 和 R: 的 E: 有 W: 人 Q: 我
Note that the root of each character lies on its corresponding key.
We will now analyze some sample characters, following the rules of Wubi typing that have been outlined, as well as incorporating Regions 1 and 2. From now on, only the rule used to derive the code and the code will be given; by now, you should understand the basic processes.
| 秀: | This is another simple second-level character. The code is TE. 手: It may seem as if, since this character appears on the key 32R, the code would be R plus the first, second, and last stroke. This code would work, but 手 is a commonly used character; it turns out that Wubi requires only R plus the first stroke, or RT. This is one of the many ways Wubi speeds up the typing process. |
| 夫: | This is one of the many characters that contains debatable roots. Are the roots 一 and 大 (GD) or 二 and 人 (FW)? In fact, the answer is the latter. Keep an open mind: If one method does not work, try another. |
| 垢: | The Wubi code for this character, simply, is FRGK. Try to find these roots on Diagram 3. |
| 入: | This character may seem to fit on the 34W key, just as 人 and 亻 do. However, if examined closely, it is quite a different character. Its roots are not part of the 34W key; the roots are 丿 and 丶. Thus, the Wubi code for 入 is TY. |
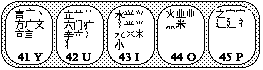
Diagram 7: Region 4
Glance over region 4 and get a general sense of the roots on each key. Remember that every root begins with a right-falling stroke (or a dot). The first-level characters are as follows:
Y: 主 U: 产 I: 不 O: 为 P: 这
Note that the root of each character lies on its corresponding key.
We will now analyze some sample characters, following the rules of Wubi typing that have been outlined, as well as incorporating Regions 1 through 3 in the example characters.
| 就: | A commonly-used character, 就 is only a second-level Wubi code, made up of its first two roots (the dot, line, and box and 小. Its code is YI. |
| 样: | Another simple character, the code for 样 is SUD. |
| 提: | The code for this character is RJGH. |
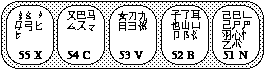
Diagram 8: Region 5
Glance over region 5 and get a general sense of the roots on each key. Remember that every root begins with a hook stroke.
The first-level characters are as follows:
N: 民 B: 了 V: 发 C: 以 X: 经
Note that the root of each character lies on its corresponding key.
We will now analyze some sample characters, following the rules of Wubi typing that have been outlined.
| 帮: | The roots, in order, are 三, 丿, 阝, 冂, 丨. Thus, the code for 帮 is DTBH. |
| 魏: | The first two roots are 禾 and 女. The third root, in Wubi, is neither 丿 nor 田. Rather, it is 白. As noted in Section 2.4, no other characters' codes are TVR followed by another character. Thus, the last key for 厶 is not necessary; TVRC is reduced to TVR. |
| 伟: | The roots are 亻, 土, the hook, and 丨. Thus, its code is WFNH. |
[TOP]
The magic of Wubi is its ability to isolate the desired roots of a character from four keys, which contain between three and ten roots each. However, Wubi logic cannot always isolate characters based on root information. In these cases, of course, Wubi conjures up more magic.
First, a few examples: What distinguishes 叭 from 只, since the roots are identical? What distinguishes 沐 from 洒 and 汀, since the second roots of each character appears on the same key? From what we have learned so far about Wubi coding, nothing does. The Isolation Rule, however, dictates how.
It turns out that the Isolation Rule is necessary when two conditions are met: First, that the character consist of less than four roots, and second, that these, alone, do not produce the desired character.
Clearly, the difference between 叭 and 只 is the configuration of the character as a whole. 叭 has a left-right configuration, while 只 has an up-down configuration. The only configuration in addition to left-right and up-down is the miscellaneous configuration. It includes roots such as 里, whose roots intersect, and 国, whose roots are contained in another root. Diagram 9 describes these regions:
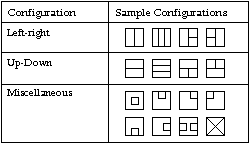
Diagram 9: Overall Character Configurations
In the second case -- 沐, 洒, and 汀 -- not only the second roots of each character distinguish the characters, but also the last stroke of the entire character distinguishes them. To continue the example, the last stroke of 沐 is 丶, of 洒 is 一, of 汀 is 丨.
In an effort to isolate any character in a rule that covers both the configuration and the last stroke circumstances, the Wubi Isolation Rule states the following:
If the character contains less than four roots and if entering just these roots does not produce the character, then the last key -- the isolating key -- can be determined by using Diagram 10.
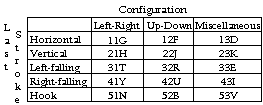
Diagram 10: The Isolation Rule
To put the first examples to rest, their codes are as follows:
| 叭: | The code, based only on the roots, is KW. Since the character has a left-right configuration, and since the last stroke is 丶, the isolating key is 41Y. Thus, the code for 叭 is KWY. |
| 只: | The code, based only on the roots, is KW. Since the character has an up-down configuration, and since the last stroke is 丶, the isolating key is 42U. Thus, the code for 只 is KWU. |
| 沐: | The code, based only on the roots, is IS. Since the character has a left-right configuration, and since the last stroke is 丶, the isolating key is 41Y. Thus, the code for 沐 is ISY. |
| 洒: | The code, based only on the roots, is IS. Since the character has a left-right configuration, and since the last stroke is 一, the isolating key is 11G. Thus, the code for 洒 is ISG. |
| 汀: | The code, based only on the roots, is IS. Since the character has a left-right configuration, and since the last stroke is 丨, the isolating key is 21H. Thus, the code for 汀 is ISH. |
| 里: | The code, based only on the roots, is JF. Since the character has a miscellaneous configuration (日 and 土 overlap), and since the last stroke is 一, the isolating key is 13D. Thus, the code for 里 is JFD. |
[TOP]
Until now, this manual has only dealt with entering single characters. However, Wubi logic does incorporate rules for commonly-used, multi-character combinations, and the codes for these combinations remain within the four keystroke limit. The rules are surprisingly simple. However, one rule is extremely important to remember: When using multi-character combinations, the shortened codes as described in Section 2.4 may not be used. Only the verbose codes may be used.
For commonly-used, two-character combinations, the rule is to enter the first two roots of each character. For example, the code for 经 (jing1) is XCA, and the code for 常 (chang2) is IPKH. But, together, the code for the combination 经常, which means day-to-day, is XCIP. Other examples follow:
| 机器: | The roots of this combination are 木, 几, 口, and 口. Thus, the code is SMKK. |
| 汉字: | The roots of this combination are 氵, 又, 宀, and 子. Thus, the code is ICPB. |
The rule for commonly-used, three-character combinations is to enter only the first roots of the first two characters and to enter the first two roots of the third character. For example, the codes for 计算机 (ji4 suan4 ji1) would be YF, THA, and SM, respectively. Together, the code for the combination is simply YTSM. Other examples follow:
| 可能性: | The roots of this combination are 丁, 厶, 忄, and 丿. Thus, the code is SCNT. |
| 小朋友: | The roots of this combination are 小, 月, 厂, and 又. Thus, the code is IEDC. |
The rule for commonly-used combinations of more than three characters is to enter the first root of the first three and of the last character in the combination. For example, 五笔字型 (Wu3bi3zi4xing2) consists of four characters, and the first roots of each character are 一, 竹, 宀, and 一, respectively. Therefore, the code for 五笔字型 is GTPG. Other examples follow:
| 一分为二: | The roots of this four-character combination are 一, 八, 丶, and 二. Thus, the code for this combination is GWYF. |
| 集体所有制: | The code for this five-character combination is WWRR. |
| 人民大会堂: | The code for this five-character combination is WNDI. |
| 中华人民共和国: | The roots of this combination, which means the People?s Republic of China, are 口, 亻, 人, and 囗. Thus, the code for this seven-character combination is KWWL. |
Z is the only letter not included in the Wubi root keyboard; it is reserved for a special function: the wildcard. If a user is unsure of one or more roots in a code, he or she may replace that letter with Z, and the program will list all characters or combinations whose code contain the given keys. For example, if a user knows that the code of 情 begins NG but cannot find the key that contains 月, he or she can enter NGZ. The list shown will be similar to this: 1 刁 2 恒 3 怀 4 情 5 司 6 屋 7 怔 8 怦 9 愫. Using the mouse, cursor keys, or numeric keypad, select the desired character. The Z can be entered anywhere and as many times as is desired. Note that not all programs that allow Wubi input use this function.
[TOP]
[TOP]
Second-level characters are formed by entering a key on the vertical axis followed by a key on the horizontal axis, as in the table below.

[TOP]
{kind=link}